
먼저 각종 패키지들을 땡겨옵니다.
참고로 저는 패키지들을 매번 입력하기 보다
import_pack.py 파일에 모두 저장한 후
from import_pack import * 명령어로 땡겨옵니다
from pandas import Series, DataFrame import pandas as pd from pandas_datareader import data from pandas.tseries.offsets import Day, MonthEnd import numpy as np import sys import matplotlib.pyplot as plt from scipy.stats import rankdata from scipy.stats import stats from scipy.optimize import minimize
먼저 수익률 데이터(rets)를 통해 variance-covariance 매트릭스를 만듭니다.
rets 데이터는 지난번 TAA 예제 데이터를 그대로 사용합니다.
위험기반 자산배분에서 가장 중요한 데이터가 바로
variance-covariance matrix (Ω) 입니다.
과거 데이터를 그냥 쓸수도 있고,
여러 추정방법론을 이용하여 추정할 수도 있습니다. :D
covmat = DataFrame.cov(rets)
먼저 Risk Parity 를 이해하기 위해서는
MRC와 RC에 대한 이해가 필수입니다.
이 둘의 단어는 아래와 같습니다.
〈 출처 - 내 책 〉

그렇다면 계산은 어떻게 할까요?
그냥 분산을 매트릭스 형태 w'Ωw 로 두고
미분만 몇번 뚝딱뚝딱 하면 쉽게 계산이 됩니다.
(요건 책에 없습니다. 그냥 후배들 교육용 강의자료에 있습니다.
친절한 센빠이 :D)
친절한 센빠이 :D)

결국 MRC와 RC를 구하기 위해서는
각 자산별 비중과 공분산행렬만 있으면 됩니다.
이를 나타내면 아래와 같습니다.
비중과 공분산행렬을 입력하면 Risk Contribution 값을 계산해 주는 함수입니다.
def RC(weight, covmat) : weight = np.array(weight) variance = weight.T @ covmat @ weight sigma = variance ** 0.5 mrc = 1/sigma * (covmat @ weight) rc = weight * mrc rc = rc / rc.sum() return(rc)
이번부터 본격적으로 Risk Parity Portfolio를 만드는 코드입니다.
variance, sigma, mrc, rc는 위에 코드와 동일하며
단지 weight만 x로 바뀌었습니다.
최적화의 최종결과물로 x가 반환되기 때문입니다.
risk_diffs는 a와 a'의 차이 입니다.
아래 수식의 목적 함수를 만들기 위해서 입니다.

sum_risk_diffs_squared 는 해당 매트릭스의 제곱의 합입니다.
위에 수식보면 이해가 되죠??
위에 수식보면 이해가 되죠??
나중에 나오겠지만, 이 값이 최소화가 되는 지점을 찾는겁니다.
이론적으로는 0이 최소지점 이겠죠?
def RiskParity_objective(x) : variance = x.T @ covmat @ x sigma = variance ** 0.5 mrc = 1/sigma * (covmat @ x) rc = x * mrc a = np.reshape(rc, (len(rc), 1)) risk_diffs = a - a.T sum_risk_diffs_squared = np.sum(np.square(np.ravel(risk_diffs))) return (sum_risk_diffs_squared)
이번에는 각종 제약조건의 함수입니다.
리스크 패러티의 제약조건은 크게 두가지 입니다.
1) 비중의 합이 1
2) 개별 비중이 0 이상
대부분 프로그래밍에서 제약조건은
블라블라 = 0
혹은
블라블라 > 0
으로 나타납니다.
먼저 블라블라 = 0 에서 블라블라를 1)의 조건으로 바꾸려면
비중의 합 - 1 = 0 으로 나타내면 됩니다.
(비중의 합 = 1 과 같죠?)
이를 나타낸게 weight_sum_constraint 입니다.
참고로 x는 나중에 반환될 비중들 입니다.
두번째 블라블라 > 0은 2)번 조건으로 바꾸면
비중 > 0 으로 나타납니다.
이를 나타낸게 weight_longonly 입니다.
def weight_sum_constraint(x) : return(x.sum() - 1.0 ) def weight_longonly(x) : return(x)
최종적으로 리스크패러티 포트폴리오를 구하는 함수입니다.
입력값은 covmat 하나만이 필요합니다.
포트폴리오 비중을 구하는 최적화는 보통 iteration 방법론을 사용합니다.
이를 쉽게 표현하면 다음과 같습니다.
여러분이 특정 요리의 최적의 맛을 압니다.
쉽게 설명하기 위해 육수와 소금만으로 재료를 사용한다고 합니다.
먼저 육수에 대충 소금을 대충 넣습니다. 짭니다.
육수를 더 넣습니다. 미지근합니다.
소금을 조금 더 넣습니다. 조금 짭니다.
육수를 조금 더 넣습니다. 밍밍해집니다.
이 작업을 최적의 맛을 구할 때 까지 합니다.
물론 계산에는 한계라는게 있기 때문에
1) 소금과 육수를 넣을 수 있는 횟수 (max iteration)
2) 어느정도 비슷한 맛이 날때까지 (tolerance)
라는 제약조건이 들어갑니다.

x0는 먼저 대충 들어갈 재료, 여기서는 비중입니다.
간단하게 1/n, 즉 동일가중을 넣습니다.
constraints 에는 각종 제약조건입니다.
아까전에 입력한 합계=1, 그리고 개별비중>0 제약조건을 넣습니다.
첫번째는 등호가 있으니 eq (equality)
두번째는 부등호니ineq (inequality) 를 입력합니다.
options에는 맛의 한계치와 소금의 합계치 입니다.
ftol은 tolerance이며, fun값이 (위에서 구한 sum_risk_diffs_squared)
해당 값보다 작아지면 최적화를 멈춥니다.
maxiter는 최대한 몇번까지 동작할까 입니다.
800번을 넘고도 최적화 값을 못구하면
그냥 못구하는구나 하고 멈춥니다.
ftol은 작게 할수록, maxiter는 크게 할수록
좀더 완벽한 답을 찾지만, 계산시간은 늘어납니다.
result는 minimize라는 함수를 씁니다.

해당 함수는 scipy.optimize.minimize [Link] 라는 패키지에 있습니다.
자세한 내용은 해당 패키지 사용설명서 보면서 쓱쓱 해보면 됩니다.
minimize(fun, x0, args=(), method=None, jac=None, hess=None, hessp=None, bounds=None, constraints=(), tol=None, callback=None, options=None)
크게보면 fun함수를 최소화해주는 값들을 찾아주며,
뒤에는 이것저것 옵션들이 많습니다.
옵션들을 쓰까쓰까!
최적화에서 가장 중요한 작업은
무슨 방법을 쎃느냐 입니다.
여기서는 SLSQP(Sequential Least Squares Programming) 을 사용합니다.
요 방법인거 같군요.
sum_risk_diffs_squared랑 constraints 들이 어떻게 들어갈지 대충 보이죠?
(요런거 재밌어하면 당신도 퀀트입니다.)
result.x에 최종 결과물이 반환됩니다.
여기서는 각 종목별 비중이겠네요.
def RiskParity(covmat) : x0 = np.repeat(1/covmat.shape[1], covmat.shape[1]) constraints = ({'type': 'eq', 'fun': weight_sum_constraint}, {'type': 'ineq', 'fun': weight_longonly}) options = {'ftol': 1e-20, 'maxiter': 800} result = minimize(fun = RiskParity_objective, x0 = x0, method = 'SLSQP', constraints = constraints, options = options) return(result.x)
result 값을 보면 다음과 같습니다.
fun은 목적함수인 sum_risk_diffs_squared,
즉 a - a.T 값입니다.
e-19승이니 무지하게 작은 값이겠죠?
jac는 자코비안 행렬 값입니다.
meassage는 잘 끝났단요
나머지는 잘 모르겠네요
x는 결과값입니다. 여기서는 종목 당 비중이겠죠

값을 구했으면 맞는지 확인을 해야겠죠?
위에서 작성한 함수를 실행하면 비중이 계산됩니다.
위에서 작성한 함수를 실행하면 비중이 계산됩니다.
wt_erc = RiskParity(covmat)
먼저 동일가중 포트폴리오의 Risk Contribution을 계산해 봅니다.
위에서 작성한 RC함수를 통해 구할 수 있습니다.
뭔가 지 맘대로 입니다. 4,5 번째 종목은 마이너스가 나오기도 합니다.
뭔가 변동성이나 상관관계가 엄청 낮은 종목이란 얘기겠죠?
wt_ew = np.repeat(1/rets.shape[1], rets.shape[1]) rc_ew = RC(wt_ew, covmat) DataFrame(rc_ew).plot(kind = 'bar')

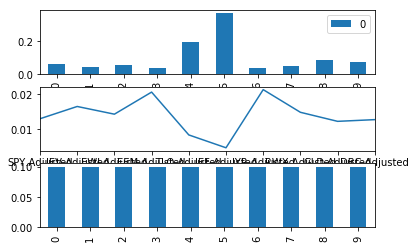
이번에는 위에서 구한 Risk Parity 포트폴리오의 결과들을 구합니다.
파이썬 한지 몇주 안되서 그림은 이쁘지가 않습니다 ㅠㅠ
첫번째는 각 종목별 비중,
두번째는 각 종목별 변동성
세번째는 각 종목별 Risk Contribution 입니다.
역시나 변동성이 낮은 4, 5번 종목에 비중이 많으며
모든 종목들의 RC는 모두 같음이 보입니다.
제대로 구해졌군요 :D
하지만 R에서는 이 모든 작업이 단 3줄로 끝납니다.
FRAPO 패키지를 이용해서요....
결과도 exactly 동일합니다........ FXXX!!!!!
결과도 exactly 동일합니다........ FXXX!!!!!
library(FRAPO) covmat = cov(rets) wt_erc = Weights(PERC(covmat, percentage = FALSE))

사실 Risk Parity 에서는 Risk를 Risk Contribution 으로 정의합니다만,
다른 형태로 정의할 수도 있습니다.
또한 코드를 살짝만 바꾸면
Risk Parity 아닌 Risk Budgeting Portfolio를 만들수도 있습니다.
연습한다 생각하고 한번 해보세요!!!
표준편차가아닌 분산으로 MRC와 RC를 구하면 어떨까하고 시도해보니, 아래와 같이 RC는 분산의 두배가 되는 것 같은데..계산이 잘못된건지 뭔지 잘 모르겠네요^^;;
답글삭제MRC = 2Ωw
RC = 2wΩw
생각해보니 분산은 2차함수이므로 미분값이 1차함수가 되고, 1차함수의 넓이는 1/2를 곱해주어야 하는 것 같네요^^
답글삭제표준편차는 1차함수라서 미분값에 w를 곱하면 넓이가 되는 것 같구요.
코드에 조금 오류가 있네요
답글삭제a = np.reshape(rc, (len(rc), 1)) -> a = np.reshape(rc, len(rc))
risk_diffs = a - a.T -> risk_diffs = a - x.T
이렇게 바꾸셔야 할것 같습니다.
개소리였네요....흠 자꾸 차원 에러가 나는데 이유를 모르겠네요
삭제안녕하세요 혹시 리스크패러티 전략도 24개월 수익률 에 대한 공분산행렬에 한 달 주기의 리밸런싱 코드도 가능할까요....
답글삭제